








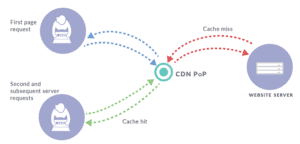
The first visit on a website after a cache is first set up or after it expires goes through an empty or ‘cold’ cache, and is met with a ‘cache miss’. The cache passes on the request to the origin server to retrieve the file and transmits it to the browser. Of course, it also retains the file in the cache, which is now full or ‘warm’. Each subsequent user who visits the same site before the cache expires will then be served the file from the cache. This is referred to as a ‘cache hit’.
In summary, a cache hit is when a request is served by the cache and a cache miss is when it is served by the origin server. In other words, a cold cache doesn’t yet contain any files, and a warm cache already contains files and is ready to serve visitors.
Cache warming: pros and cons
It is in your interest for Internet users to meet a cache hit to be served quickly. However, unless sites engage in cache warming, some visitors will be met with a cache miss after the content expires or the cache is cleared. This gives these visitors a worse experience.
Warming up the cache involves artificially filling the cache so that real visitors always have cache access. Essentially, it prepares the cache for visitors (hence the term ‘warming’, as in warming up a car engine) rather than allowing the first visitor to be served a cache miss. This ensures that all visitors have the same experience.
While cache warming offers benefits, it’s important to watch out for a couple of points. Here are some of the problems that can arise when implementing cache warming.
Too many cache servers to warm
If the pages are cached on a CDN with several hundred edge servers, the system will have to set up all of these caches. The site can use an indexing bot, or crawler. This crawler will have to visit the website multiple times and from multiple locations to make sure that each cache is filled.
In this case, the most reasonable strategy is to target only certain nodes of the CDN – those referred to as the principal nodes (origin shield in origin shieldKeyCDN, regional edge cache in Cloudfront). This reduces the scale of the task.
At Fasterize, pages are generally cached on the platform. As such, this problem doesn’t arise.
Page lifespans that are too short
If the cache duration is just a few minutes, setting up a crawler won’t be effective. It won’t have enough time to trawl through the entire catalogue before the pages it visits expire.
In this situation, a compromise needs to be found – only pre-loading key site pages.
An origin server that can’t cope with regular crawling
Being visited by a crawler can result in a non-negligible load on undersized origin servers. Essentially, the crawler requests pages that are loaded from the origin server infrequently, which can result in requests that put heavy strain on the origin server’s database.
In this case, the solution is to:
- reduce the number of pages crawled,
- or reduce the crawling speed,
- or carry out crawling at quieter times.
Too many possible variations per page
If there are hundreds of versions of the product page (one version for each physical store, for example), the number of pages to be processed may be too high for the allocated crawling time. In this case, the best thing is to determine which versions to prioritize so the crawler only visits major versions of each page.
The Fasterize crawler: how does it work?
Our crawler has two operating methods:
- crawling through the URLs included in the website’s sitemap
- crawling through a list of URLs provided by the client
The crawler only takes the URLs of pages included in the sitemap into account. Image URLs are not crawled. We recommend using this mode because of its simplicity. However, if the sitemap can’t be used because it is too big or not up-to-date, a static list of URLs can be provided. The crawler then goes through this list from start to finish.
The crawling speed can be configured:
- the number of bots crawling at once (set to 4 by default)
- the wait time between each request (set to 0.2 seconds by default).
The User-Agent header used by the crawler can also be configured. By default, it is: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36k FstrzCrawler.
Finally, the request headers can also be customized. This gives significant flexibility in a number of cases:
- dealing with several variants depending on the fstrz_vary variant cookie
- requiring mandatory or optional refreshing of each page.
- refreshing several Fasterize caches: the main cache or the cookieless cache.







