








Explorons en détail le sujet du préchauffage du cache. Partons à la découverte des différences entre Cache hit et Cache miss, les avantages et désavantages du préchauffage du cache, et ce que nous avons mis en place via notre moteur pour optimiser les performances de votre site et offrir la meilleure expérience possible à vos utilisateurs.
Pour améliorer la vitesse de chargement des pages web, la mise en place d’une stratégie de cache cohérente et performante est essentielle.
En termes de stratégie de cache, notre solution SaaS propose de nombreuses fonctionnalités pour accélérer le chargement des ressources par le navigateur :
- le Smart Cache, qui permet la mise en cache des contenus dynamiques sur une page,
- le Cookieless cache, pour optimiser la vitesse des pages pour les utilisateurs sans session active,
- la gestion de plusieurs variations de page pour une version mobile, une variation de langue ou selon le magasin.
Cependant, le système de cache de Fasterize n’est performant que s’il est chaud et correctement alimenté. L’alimentation de ce système de cache se fait de façon passive au fur et à mesure des requêtes entrantes effectuées par les internautes. Le préchargement du cache via un crawler est d’autant plus intéressant lorsque :
-
- le trafic du site est faible en comparaison de la taille du catalogue produit
- ou que la probabilité pour que plusieurs utilisateurs demandent la même variation d’une page est faible.
Cache hit vs. Cache miss
Le cache de Fasterize stocke une ou plusieurs variations des fichiers ressources constituant une page web, afin d’apporter une réponse plus rapide aux requêtes du navigateur. En mettant en cache des copies de données telles que les images, le code CSS et le code HTML, le serveur d’origine n’a pas besoin de générer ces fichiers à chaque fois qu’un nouvel utilisateur accède au site web. Cela améliore le temps de chargement de la page, et réduit la pression sur le serveur d’origine. Ainsi, un site web peut servir plus d’utilisateurs à la fois !
Les sites de e-commerce mettant constamment à jour l’inventaire de leurs produits, les fichiers expirent après une période définie qui peut aller d’une minute à plusieurs heures. Or, chaque fois qu’un fichier dans le cache expire, celui-ci doit être récupéré à nouveau depuis le serveur d’origine.
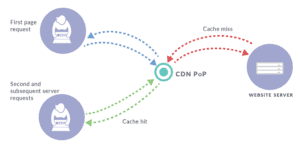
La première visite, après l’installation initiale d’un cache, ou l’expiration d’un cache, passe par un cache vide ou froid et rencontre alors un « cache miss« .
Le cache transmet la requête au serveur d’origine pour obtenir une réponse et récupérer le fichier, afin de le transmettre au navigateur. Bien sûr, il conserve par la même occasion le fichier dans le cache qui est donc complet, ou chaud. Chaque utilisateur suivant qui visite ce même site avant l’expiration du cache sera alors servi depuis le cache. On parle alors d’un « cache hit« .
En résumé, un cache hit correspond à une requête ayant été servie par le cache alors qu’un cache miss correspond à une requête servie par l’origine. Autrement dit, un cache froid ne contient pas encore les fichiers, et un cache chaud contient déjà des fichiers et est prêt à servir les internautes.
Préchauffage du cache : avantages et inconvénients
Il y a tout intérêt à ce que les utilisateurs rencontrent un cache hit pour être servis rapidement. Cependant, à moins que les sites ne se mettent à préchauffer le cache, certains internautes rencontrent un cache miss après l’expiration du contenu ou le vidage du cache. L’expérience est alors dégradée.
Le préchauffage du cache consiste alors à remplir artificiellement le cache, de sorte que les visiteurs réels accèdent au cache. Essentiellement, cela prépare le cache pour les internautes (d’où le terme « préchauffage », comme pour un moteur de voiture), plutôt que de laisser le premier visiteur avec un cache miss. Ainsi, tout le monde bénéficie de la même expérience de qualité.
Si le préchargement du cache est une technique intéressante, il faut cependant rester vigilant.
Voici quelques difficultés que vous pouvez rencontrer lors de la mise en place d’un préchargement du cache.
Trop de serveurs de cache à préchauffer
Si les pages sont mises en cache sur un CDN ayant plusieurs centaines de serveurs edge, le système devra mettre en place tous ces caches. Le site peut utiliser un robot d’indexation ou crawler. Ce robot devra se rendre sur le site web à plusieurs reprises et à partir de plusieurs emplacements pour s’assurer que chaque cache est rempli.
Dans ce cas, la stratégie la plus raisonnable est de ne cibler que certains nœuds principaux du CDN (origin shield de KeyCDN, regional edge cache de Cloudfront). Cela réduit l’ampleur de la tâche.
Chez Fasterize, les pages sont généralement mises en cache sur la plateforme. Le problème ne se pose donc pas.
Une durée de vie des pages trop courtes
Si la durée de cache est de quelques minutes, la mise en place d’un crawler ne sera pas efficace. Le crawler n’aura pas le temps de parcourir l’ensemble du catalogue que les pages visitées auront déjà expiré.
Dans ce cas de figure, il faudra trouver un compromis : ne précharger que les pages clés du site.
Un serveur d’origine ne pouvant pas tenir la charge d’un crawling régulier
Le passage d’un crawler peut générer une charge non négligeable sur des origines sous-dimensionnées. En effet, le crawler va demander des pages peu chargées ce qui peut induire des requêtes sollicitant fortement la base de données à l’origine.
Dans ce cas, il faut :
- réduire le nombre de pages crawlées,
- ou réduire la vitesse de crawling
- ou encore effectuer un crawling aux heures creuses de la journée.
Trop de variations possibles par page
Si la page produit se décline sous des centaines de versions (une version par magasin physique par exemple), le nombre de pages à traiter peut être trop important par rapport aux temps de crawling alloués. Dans ce cas, il est souhaitable de prioriser les versions pour ne crawler que les versions principales de chaque page.
Comment fonctionne le crawler de Fasterize
Notre crawler a deux modes de fonctionnements :
- le parcours des URLs présentes dans le sitemap du site,
- le parcours d’une liste d’URLs fournies par le client
Le crawler ne prend en compte que les URLs des pages du sitemap. Les URLs des images ne sont pas crawlées. Nous conseillons ce mode en raison de sa simplicité. Cependant, si le sitemap n’est pas exploitable car trop large ou périmé, il est possible de fournir une liste statique d’URLs. Cette liste est alors parcourue du début à la fin.
La vitesse de crawling est paramétrable :
- le nombre de robots crawlant en parallèle (par défaut 4)
- le temps d’attente entre chaque requête (par défaut 0.2 sec).
Il est également possible de configurer l’en-tête User-Agent utilisé par le crawl. Il s’agit par défaut de Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36k FstrzCrawler.
Enfin, les en-têtes de la requête sont elles aussi personnalisables pour plus de flexibilité :
- adresser plusieurs variations selon le cookie de variation fstrz_vary,
- imposer un rafraîchissement obligatoire ou optionnel de chaque page,
- rafraîchir plusieurs caches de Fasterize : le cache principal ou le cookieless cache.
Restez informés de notre actualité et de nos fonctionnalités,
inscrivez-vous à notre newsletter :







