

Pour compléter notre billet sur le waterfall, nous publions ici une traduction de l’article original de Matthew Hobbs sur son blog nooshu.com (en anglais). L’article original est régulièrement enrichi, nous ajouterons les nouveaux éléments au fur et à mesure. Notez que certains des liens présents dans cet article renvoient vers des publications originales également en anglais.
Je suis souvent amené à lire et analyser des waterfalls sur WebPageTest (WPT), mais comme j’ai l’impression d’avoir une mémoire de chimpanzé (pas de poisson rouge, c’est un mythe), j’ai tendance à oublier certains détails et leur signification. J'ai donc décidé de rassembler de nombreuses informations dans cet article auquel je pourrai me référer.
Si ça vous est aussi utile, ou que vous pensez que j’ai oublié quelque chose, faites-moi signe.
L’interface de base
Voici l’interface de base d’un waterfall pour laquelle nous allons détailler chaque élément :

1 - Key (légendes)
Les légendes donnent plusieurs sortes d’informations :
- Le statut de la connexion (résolution DNS, établissement de la connexion, négociation TLS*)
- Le type de ressources demandées (ex. HTML, images, etc.)
- Les événements divers (“wait”, exécution de JavaScript)
Chaque ressource est représentée par 2 couleurs, une nuance claire et une nuance foncée. La couleur claire indique le moment où le navigateur a demandé la ressource.
La couleur foncée indique quant à elle le moment où la ressource est en train de se télécharger.
Pour plus de précisions, je vous recommande ce post de Pat Meenan.
L’élément “wait” est nouveau dans WPT. Il correspond au temps écoulé entre le moment où le navigateur découvre la ressource sur la page et celui où il la demande au serveur.
2 - Request list (la liste des requêtes)
C’est la liste des ressources que le navigateur a découvertes sur la page et l'ordre dans lequel elles ont été demandées. Le numéro de la demande se trouve tout à gauche, ainsi qu’un verrou jaune si la requête est effectuée via une connexion sécurisée (HTTPS).
3 - Request timeline (la chronologie des requêtes)
La timeline montre le temps, le long de l'axe horizontal (x), que prend chaque requête sur l'axe vertical (y). Vous pouvez ainsi observer le cycle de vie d'une requête faite par le navigateur : de la découverte (“wait”) à la requête, jusqu’au téléchargement de la ressource.
Idéalement, cette timeline doit être la plus courte possible car c’est le signe d’une bonne performance : en effet, plus elle est courte, plus la page se charge rapidement pour l’internaute.
4 - CPU Utilisation (utilisation du CPU)
Ce graphique illustre l'utilisation du CPU du device par le navigateur. Il montre la quantité de CPU utilisée pour la page testée à chaque étape, variant de 0 à 100 %.
5 - Bandwidth In (bande passante)
Cet indicateur montre le moment où les données arrivent sur le navigateur. Ce graphique permet de distinguer les phases de travail “utiles” du navigateur par rapport au temps perdu. Sachez que l’échelle absolue peut être ignorée parce qu’elle manque de précision. Vous pouvez utiliser l'option “Capture network packet trace (tcpdump)” dans l'onglet Avancé de la page d'accueil de WebPageTest si vous souhaitez des résultats plus précis.
6 - Browser Main Thread (le fil principal du navigateur)
Voici ce que chacune des couleurs signifie :
- Orange - Analyse, évaluation et exécution de scripts
- Violet - Mise en page / rendering
- Vert - Eléments visuels
- Bleu - Analyse HTML
En observant ce graphique, il est possible de détecter si le CPU devient un goulot d'étranglement.
7 - Page is Interactive (interactivité de la page)
Grâce à ce graphique, vous pouvez repérer quand le “main thread” est bloqué. Les blocs rouges indiquent par exemple ici qu’il a été bloqué pendant 100 ms (ce qui empêchera également les actions telles que les clics sur des boutons). La couleur verte indique que le thread principal n’est pas bloqué.
NB : il reste possible de scroller pendant les phases bloquées en rouge, étant donné que le scrolling est généralement traité en dehors du thread principal par la plupart des navigateurs.
Les lignes verticales
Sous le titre “Waterfall View”, vous pouvez pouvez voir les légendes qui correspondent aux lignes de couleur verticales :

Mais que signifient-elles ?
Start Render - Vert
C'est la fin de la page blanche, soit l’instant où l’internaute voit les premiers pixels apparaître. Les pixels peuvent provenir de n'importe quel élément (image de fond, bordures, etc.), pas nécessairement d’un contenu pertinent. Cette mesure est obtenue en analysant les frames vidéo capturées lors du chargement de la page.
RUM First Paint - Vert clair
C’est le moment où le navigateur restitue à l’écran tout ce qui est visuellement différent d’avant la navigation (c’est-à-dire l’écran vide pour WPT). Cette métrique provient de l'API des navigateurs, quand le navigateur indique qu’il montre le premier pixel. Pour cette raison, cette ligne verticale n'est visible que si le navigateur prend en charge l'API Paint Timing.
DOM Interactive - Jaune
Il s’agit du moment où le navigateur a fini d’analyser le HTML, et que le DOM est construit. Malheureusement, cette métrique n’est pas totalement fiable.
DOM Content Loaded - Rose
C’est le moment où le code HTML est chargé et analysé, et le navigateur a atteint la fin du document. Tous les scripts bloquants sont aussi chargés et exécutés. A ce stade, le DOM est complètement finalisé.
On Load - Mauve
C’est le point de départ du chargement de la fenêtre. Tous les objets sont dans le DOM et le chargement de toutes les images et de tous les scripts est terminé.
Document Complete - Bleu
L’onload est déclenché et tout le contenu de l'image statique est chargé. Les modifications de contenu provoquées par l'exécution de JavaScript peuvent ne pas être incluses.
Les timings horizontaux
A présent, voyons la timeline - ou chronologie - des requêtes (3). A quoi fait référence le bloc horizontal et que contient-il ? Eh bien, si vous cliquez sur l’une des requêtes, vous verrez apparaître une pop-up avec un grand nombre d’information comme celle-ci :

Explorons maintenant quelques-unes des différentes requêtes de cette waterfall view.
Requête 1 - Le HTML
Dans le cas ici présent, le navigateur demande le document HTML. Dans le même temps, il doit également configurer la connexion au serveur. Dans les détails de la requête, les temps suivants sont indiqués :
- Discovered : 0.011 s
- Request Start : 0.116 s
- DNS Lookup : 27 ms
- Initial Connection : 25 ms
- SSL/TLS Negotiation : 43 ms
- Time to First Byte : 315 ms
- Content Download : 40 ms
J’ai annoté la requête pour montrer à quoi correspondent chacun de ces temps :

En ajoutant la résolution DNS, la connexion initiale, la négociation TLS, le Time to First Byte (TTFB) et le temps de chargement du contenu, on arrive aux 450ms que l’on voit affichées tout de suite après la fin de la requête.
Notez que WPT suit un protocole spécifique :
- Si le temps correspond à une durée, elle est exprimée en millisecondes (ms), par ex. la résolution DNS a pris 27ms.
- Si le temps correspond à un point de départ, il est exprimé en secondes, par ex. la requête a commencé à 0,116s.
Requête 7 - Un script tiers en JavaScript
Cette requête est différente de celles examinées précédemment parce que le fichier vient d’un domaine tiers. Les détails sont les suivants :
- Discovered : 0.473 s
- Request Start : 0.702 s
- DNS Lookup : 28 ms
- Initial Connection : 39 ms
- SSL/TLS Negotiation : 153 ms
- Time to First Byte : 48 ms
- Content Download : 9 ms
Notez que le navigateur doit à nouveau suivre tout le processus de connexion (DNS, connexion, négociation TLS) car le fichier est sur un autre domaine. Cela ajoute une quantité non négligeable de temps à la requête (28 + 39 + 153 = 220 ms).

Autre point intéressant : le script s’exécute en environ 200 ms une fois le téléchargement terminé. Aucune information sur cette exécution n’est proposée, mais vous pouvez la voir dans le waterfall sous forme de lignes rose pâle après la requête, et en orange dans la partie “Browser Main Thread” (6) qui indique l’analyse, l’évaluation et l’exécution des scripts.
Requête 15 - Un fichier PNG
Dans cette requête, le navigateur a découvert un fichier PNG et le demande au serveur. Voici les timings correspondants :
- Discovered : 0.652 s
- Request Start : 0.824 s
- Time to First Byte : 214 ms
- Content Download : 28 ms
Le délai est calculé en faisant la différence entre le moment de la découverte du fichier et le moment du début de la requête. Ce délai est ainsi constitué par le temps écoulé entre le moment où le navigateur trouve pour la première fois la ressource et celui où il peut envoyer une requête au serveur pour le récupérer.

Le délai après cette requête est le temps écoulé entre la requête en cours et sa finalisation (premier octet + téléchargement du contenu). Comme une connexion au domaine a déjà été établie (NdT : on est en HTTP/2), il n’est pas nécessaire de recourir une nouvelle fois à la résolution DNS, connexion, négociation TLS.
Requête 23 - Un fichier GIF déplacé
La requête 23 peut sembler banale, pourtant, il se passe quelque chose d’anormal. Le fond de la requête est en jaune, ce qui indique un code d’état de réponse du serveur (status code) qui n’est pas le 200 habituel. En effet, il s’agit ici d’un code 302, ce qui signifie que le fichier GIF demandé a engendré une redirection. Les réponses avec un code de statut 3xx ont toutes un fond jaune. Les détails de la requête affichent les informations suivantes :
- Error/Status Code : 302
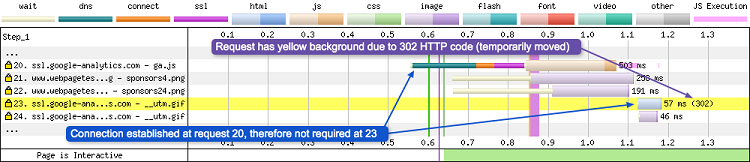
Notez que la requête 23 ne nécessite pas l’établissement d’une connexion TCP car c’est déjà fait pour ce domaine à la requête 20.
Les status codes d’erreur 4xx et 5xx sont affichés de la même manière, seul le fond est rouge, comme dans l'exemple ci-dessous (cette image provient d'un test différent) :

Les détails de la requête donnent les informations suivantes :
- Error/Status Code: 404
Notez ici la couleur de la réponse correspondant à cette ressource : plutôt que d'être mauve (la couleur attendue pour une image), elle est bleue. Cela signifie qu'il s'agit d'un contenu HTML, autrement dit, c’est le serveur qui répond avec une page 404 car la ressource est introuvable.
Téléchargement par fragments (download chunks)
Autre détail qui peut attirer votre attention : les rayures verticales pour chacune des requêtes. Comme mentionné précédemment, la couleur claire signifie que la requête est faite et que le navigateur attend une réponse. La couleur foncée indique que des octets sont délivrés au navigateur pour cette ressource. Il arrive que tout ne se produise pas simultanément, d’où les rayures qui témoignent du fait que le navigateur récupère des fragments au fur et à mesure - ce sont les flèches rouges ci-dessous qui pointent vers ces “download chunks”.

C’est particulièrement visible lorsqu'une technique de HTML early flush est utilisée (voir ci-après - requête 2) ou si un grand nombre d'éléments sont téléchargés en parallèle et se font concurrence pour obtenir des ressources (requêtes 3 à 9).
Notez que la courbe qui montre la bande passante, en bas, est au maximum de 1,6 à 2,5 secondes. Vous constatez peut-être que cette fragmentation perdure même quand la consommation de bande passante a diminué (plus de 2,6 secondes).
Mais alors, que se passe-t-il ici ? Eh bien, le nombre de connexions parallèles a diminué, de sorte que le téléchargement en parallèle est moins important. Cependant, les connexions créées dans les requêtes 12 à 15 en sont encore à la phase de démarrage lent du protocole TCP (TCP slow start - NdT : parce que cette fois-ci, nous sommes en HTTP/1.1). Par conséquent, les ressources sont toujours en concurrence pour la bande passante qui est désormais limitée.
Scénarios habituels
Voici quelques cas de figure courants observés dans un waterfall WPT. J'en ajouterai d'autres au fil du temps.
DNS-prefetch
DNS Prefetch fait partie du Resource Hints Working Draft. Il permet d’indiquer au navigateur qu’une recherche DNS va bientôt être nécessaire pour un autre domaine. Ainsi, la résolution peut être lancée sans attendre. Au moment où le domaine est réellement requis, le navigateur n’aura plus qu’à compléter la négociation TCP et la négociation TLS facultative. C’est similaire à l'exemple de préconnexion ci-dessous, en ce sens que l’élément “flotte” dans la timeline. Mais ici, seule la résolution DNS (vert) est visible.

Notez à quel moment le dns-prefetch intervient dans la timeline : presque immédiatement après le téléchargement et l’analyse du HTML. Il est facile de voir la différence si vous le comparez aux négociations de connexion qui se déroulent dans les requêtes 5 et 7, où preconnect est utilisé.
Preconnect
Preconnect fait partie du Resource Hints Working Draft. Cela permet d’indiquer au navigateur qu’il faudra bientôt se connecter à un domaine donné. En anticipant cette connexion, les requêtes sont envoyées plus vite et le téléchargement des ressources est plus rapide.

Comme vous pouvez le voir dans l'image ci-dessus, la préconnexion semble “flotter” dans la timeline. Cela se produit bien avant que la requête réelle pour l'image ne soit faite. Le navigateur se sert de cet indicateur (hint) pour se connecter à l'avance, avant que cela ne soit nécessaire. Pour plus d'informations sur les indications de préconnexion, je vous recommande de lire ce post d'Andy Davies.
Prefetch
Prefetch fait partie du Resource Hints Working Draft. Il permet d’indiquer au navigateur d’anticiper la récupération d’une ressource (par exemple, un document CSS, JS, HTML) pour la navigation en cours ou pour une navigation ultérieure. Par exemple, si vous savez que la majorité de vos internautes accède à une page spécifique à partir de votre page d’accueil (comme une page d’identification), vous pouvez utiliser prefetch afin que cette page spécifique existe déjà dans la mémoire cache du navigateur. Dans l'exemple ci-dessous, j’anticipe la récupération d’un document HTML faisant partie du parcours de l’internaute :
Avec Prefetch

Le prefetch est visible à la requête 19 en bleu (HTML). Ce code HTML est alors simplement stocké dans le cache du navigateur, il n’est pas analysé. Vous pouvez le vérifier dans le waterfall en consultant la partie “Browser main thread”. Pendant le preftech, aucune activité n’est visible dans le fil principal.
Sans Prefetch

WebPageTest nous donne des informations sur le fait qu’il s’agit d’indicateurs pour le prefetch :
- Priority : IDLE (onglet Details)
- Purpose : prefetch (onglet Request)
Tenez compte du niveau de priorité du prefetch. Dans WebPageTest, lors de tests Chrome, il est répertorié comme priorité IDLE. C’est la priorité la plus basse dans DevTools (conformément au document Resource Fetch Prioritization and Scheduling in Chromium de Chromium). Ainsi, prefetch est une option, souvent en priorité faible, et sera chargé le plus tard possible par le navigateur. C’est en cela qu’il diffère du préchargement (preload) qui est obligatoire et avec une priorité élevée. Une ressource chargée à l'aide du preload bloque le rendu de la page, alors faites-en bon usage, sinon vous risquez de dégrader vos performances.
Prerender
Prerender fait partie du Resource Hints Working Draft. Il permet d’anticiper le déroulement de navigations à venir (ce qui suppose un suivi avec des outils d’analyse). En décembre 2017, avec la sortie de Chrome 63, Google a remanié le fonctionnement de prerender. Voici une brève explication avant et après :
- Avant Chrome 63 : Chrome recherchait l'élément <link rel = "prerender"> et créait une page masquée pour l'URL indiquée par celui-ci. Invisible pour l'internaute, cette page était téléchargée, y compris toutes les ressources dépendantes, et tout le code JavaScript exécuté. Si l’internaute accédait à la page, la page “pré-générée” était remplacée dans l’onglet en cours, ce qui donnait l'impression d'un chargement instantané. Mais cette méthode présentait quelques inconvénients. Premièrement, l’utilisation de la mémoire était importante pour maintenir la page masquée, ce qui était inadapté pour les appareils bas de gamme. Deuxièmement, étant donné que les interactions ne devaient pas se produire avec une page pré-générée (comme l’utilisateur.rice ne la voit pas), la tâche devenait trop complexe alors que l’objectif final était de générer effectivement la page. Cette implémentation du prerender a donc été abandonnée.
- Depuis Chrome 63 : Depuis la sortie de Chrome 63, l'indicateur prerender est toujours reconnu et suivi par Chrome, mais son traitement a changé. Chrome utilise désormais une technique appelée “NoState Prefetch” lorsqu'il détecte un élément <link rel = "prerender"> . Il n’est alors suivi que si ces deux conditions sont remplies : l’internaute n’utilise pas un appareil bas de gamme et n’est pas sur une connexion mobile. Dans ce cas, la page est téléchargée et analysée pour identifier les ressources à télécharger. Elles sont alors téléchargées et mises en cache avec la priorité la plus basse possible (IDLE). Aucun JavaScript n’est exécuté sur la page pré-générée et si l’internaute y accède, le navigateur doit charger les ressources mises en cache dans un nouvel onglet (et non comme auparavant). Vous trouverez ici des précisions sur “NoState Prefetch”.
Alors, à quoi ressemble ce prerender dans un waterfall WebPageTest ?
Avec Prerender

Dans ce waterfall, vous pouvez voir la page “normale” et les ressources se chargeant de la requête 1 à 19. Le prerender se trouve à la requête 16. C’est ici que vous pouvez voir une requête pour une deuxième page HTML. Une fois terminée, les requêtes 20 à 29 sont déclenchées. Voyez le nombre de requêtes avec un fond jaune et un status code 304 : c’est le signe que ces ressources existent déjà dans le cache du navigateur, du fait que la page d’accueil HTML (requête 1) les a mises ici quelques 100ms plus tôt. Notez que très peu de choses se passent dans le thread principal du navigateur (à part l’analyse de la page d’accueil qui survient parce que la requête 30 (CSS) est terminée - NdT : et que le JS de la requête 28 n'est pas bloquant). C’est la confirmation du fait que toutes les ressources sont bien stockées dans le cache du navigateur en prévision d’une utilisation à venir.
Comme pour prefetch, WPT donne quelques informations sur les ressource pré-générées afin de détecter que les requêtes ne proviennent pas d’un système de navigation d’un.e internaute standard :
- Priorité : IDLE (onglet Details)
- Purpose : prefetch (onglet Request)
NB : Le fait qu’elles sont issues d’un prerender hint n’est pas explicite, on voit seulement “prefetch”, vu que “NoState Prefetch” est utilisé.
Sans Prerender

Sans prerender, le waterfall est “standard” : seules les requêtes pour les sous-ressources de la page en cours sont visibles.
Preload
Le pré-chargement (preloading) est une recommandation du W3C. Il est utilisé pour prioriser le chargement des ressources sélectionnées. Le navigateur peut donc être prévenu du fait qu’une ressource sera absolument nécessaire bientôt et qu’il faut la charger le plus vite possible.
Cette technique est souvent utilisée lors du chargement de polices Web. Sans preload, lors du chargement d'une font, le navigateur doit d'abord télécharger le code HTML et le CSS, puis les analyser pour créer l'arborescence de rendu. Ce n’est qu’à partir de là que le navigateur peut demander la font. Cela peut conduire à ce que l’on appelle un Flash of Invisible Text (FOIT) ou Flash of Unstyled Text (FOUT). Une solution à ce problème consiste à demander le fichier de police Web immédiatement à l'aide du preload.
Avec Preload

Sans Preload

Si vous comparez les deux images ci-dessus, vous verrez que la requête pour la police au format WOFF2 préchargée intervient dès que le code HTML commence à être téléchargé à la requête 2 (bande bleu foncé). Le navigateur a analysé la balise <head>, a vu qu’il fallait pré-charger, et a immédiatement demandé le fichier.
Dans la deuxième image, le navigateur télécharge la police après le téléchargement et l'analyse des fichiers HTML et CSS. C'est seulement à ce stade que la requête pour la police au format WOFF2 peut être faite. Ainsi, lorsque preload n'est pas utilisé, la police se trouve dans la requête 11. J'ai écrit davantage sur le préchargement de police ici.
HTTP/1.1 vs HTTP/2
HTTP/2 est une itération du protocole HTTP suite à HTTP/1.1. Etant donné que HTTP/2 utilise une seule connexion TCP et multiplexe des fichiers sur cette connexion unique, la différence entre les deux waterfalls se voit facilement :
HTTP/1.1

HTTP/2

Un navigateur utilisant HTTP/1.1 demande des images via des connexions TCP distinctes, ces requêtes s’étalant dans le temps (d'où l’aspect progressif du waterfall).
Un navigateur utilisant HTTP/2, en revanche, demande toutes les images en même temps. C'est le serveur qui décide quand les images sont envoyées au navigateur et dans quel ordre.
OCSP
Online Certificate Status Protocol (OCSP) est un protocole Internet utilisé pour obtenir le statut de révocation des certificats TLS. L’un des moyens de valider un certificat pour un navigateur consiste à se connecter à un serveur OCSP pour vérification. Dans ce cas, WebPageTest affiche un waterfall qui a cet aspect :
Avec OCSP

Cette vérification OCSP a un impact négatif sur le temps de chargement. En effet, la vérification nécessite une résolution DNS et une connexion initiale au serveur OCSP. Une fois le certificat vérifié, la négociation TLS peut avoir lieu sur le domaine d'origine. Comme vous pouvez le voir, tout le waterfall est décalé. Il faut presque 2 secondes avant que la page HTML puisse être demandée !
Sans OCSP

Si vous comparez un waterfall avec et sans OCSP, vous constaterez que la négociation TLS est beaucoup plus courte sans OCSP (300 ms au lieu de plus de 1000 ms) et que, par conséquent, la demande du fichier HTML arrive beaucoup plus tôt (à 1 seconde contre 1,95 secondes). La vérification OCSP ajoute 950 ms à la requête HTML initiale sur une connexion 3G rapide. C’est énorme !
Si vous remarquez cela sur votre timeline WebPageTest, vous devez envisager d'activer l’OCSP stapling sur votre serveur.
NB : Si vous utilisez des Certificats de Validation Étendue (Extended Validation certificates, ou EV), l’OCSP stapling ne résout pas complètement le problème. Pour plus de détails, consultez ce thread technique sur Twitter.
NdT : Attention, les navigateurs n’utilisent pas forcément le mécanisme d’OCSP Stapling, notamment Chrome pour les certificats non-EV, ainsi les résultats peuvent être faussés.
La protection améliorée contre le tracking de Firefox
Firefox a activé la protection améliorée contre le tracking par défaut à partir de sa version 69 (juin 2019). Les agents sur WebPageTest ont été mis à jour à peu près au même moment. Dans de rares cas, les requêtes de protection de contre le tracking pouvaient être visibles dans les waterfalls WPT (requêtes 1 à 3) :
![]()
Selon Pat Meenan, ces requêtes devraient maintenant être exclues par défaut de façon à ne jamais être visibles.
Pré-cacher des ressources avec des Service Workers
L’usage des Service Workers se développe progressivement et l’une des nombreuses fonctionnalités qu’ils offrent est un contrôle précis des ressources mises en cache et pour quelle durée. Ils permettent aussi de pré-cacher des fichiers pour une utilisation ultérieure (par exemple, pour les fonctionnalités hors connexion). Un détail important à garder à l'esprit lors de la mise en cache de ressources via un Service Worker est que le navigateur pourrait avoir besoin de télécharger les mêmes fichiers deux fois : une fois pour le cache HTTP (cache du navigateur standard), et une autre pour le cache du Service Worker (Cache API). Il s’agit de deux caches totalement séparés qui ne partagent pas les ressources. Ces requêtes en double se voient dans un waterfall WebPageTest :

Pour les requêtes 17 et 18, vous pouvez voir que le Service Worker JavaScript est demandé, téléchargé et initialisé.
Tout de suite après, le Service Worker examine son fichier JSON pré-caché et demande toutes les ressources répertoriées.
NB : Dans l'exemple ci-dessus, la librairie Workbox est utilisée pour simplifier la mise en place et l’utilisation du Service Worker.
Les marches d’escalier de Chrome (stair-steps)
Chrome a prévu une technique de hiérarchisation qui tient son nom de la forme qu’elle donne au waterfall. Chrome examine les ressources dans la balise <head> (avant même que la page ait un <body>), puis demande, télécharge et analyse ces requêtes en premier. Le navigateur va même jusqu'à retarder les requêtes pour des ressources dans le body jusqu'à ce que les requêtes <head> soient finalisées. Ces étapes se voient mieux dans un waterfall HTTP/1.1, comme dans l'exemple ci-dessous (bien que cela se produise également avec HTTP/2) :

Dans l'image ci-dessus du site de BBC News, 8 des 9 premières requêtes concernent des ressources dans le <head>, avec seulement 1 requête pour un fichier JavaScript situé dans le <body>. La “marche” n’est pas très longue à franchir en termes de durée, environ 200 ms seulement. Toutefois, le navigateur dispose de suffisamment de temps pour concentrer tout le processeur et toute la bande passante sur le téléchargement et l'analyse de ces ressources. Par conséquent, <head> est alors configuré et prêt à fonctionner avant que les ressources <body> ne soient téléchargées et analysées. Peu de choses ont été écrites sur cette phase de “layout-blocking” dans Chrome, mais on trouve des détails dans le document Resource Fetch Prioritization and Scheduling in Chromium de Pat Meenan, ainsi que dans Chrome’s resource scheduler source code.
HTML early flush
HTML early flush a été mentionné ci-dessus dans la partie sur le téléchargement par fragments (download chunks).
Cela correspond au moment où un serveur Web envoie une petite partie du document HTML avant que la réponse HTML entière ne soit prête. Cela permet ensuite au navigateur d’analyser le code HTML qu’il a reçu et de rechercher les ressources qu’il peut ensuite demander à l’avance (par rapport au fait d’attendre l’ensemble du document HTML à télécharger, l’analyser, puis à demander les ressources découvertes).
Avec early flush

Dans l'exemple ci-dessus, le fragment HTML téléchargé par le navigateur (requête 2) contient la balise <head> qui renvoie au JavaScript, aux polices, au JSON, aux instructions de preload et de dns-prefetch. Ce code HTML est analysé et 16 requêtes sont alors presque immédiatement déclenchées, très proches les unes des autres.
NB : remarquez que je n'ai pas répertorié de requêtes CSS. CNN.com a inséré le code CSS dans une balise <style> (aucune requête de fichier CSS n'est donc faite). Ils déclenchent ensuite les requêtes CSS via du JavaScript plus tard dans le waterfall, une fois que le code JavaScript est chargé et analysé.
Sans early flush

Si vous comparez un waterfall avec et sans early flush (ici pour différents sites, malheureusement) : avec, vous constaterez que les demandes de ressources sont effectuées lors du téléchargement HTML ; alors que sans, le navigateur doit attendre la réponse complète du document HTML.
Ce n’est qu’à partir de là que le HTML pourra être analysé et que des requêtes seront adressées pour d’autres ressources de la page. Le flush permet au navigateur de faire des requêtes plus tôt dans le waterfall, et donc de réduire le temps de chargement de la page et d’augmenter la perception de vitesse (à condition d’être implémenté correctement).
Trésors cachés
WebPageTest propose quelques fonctionnalités que vous n’avez peut-être pas remarquées. Voici quelques exemples que j'ai trouvés utiles.
Le lien entre le filmstrip et le waterfall
Cela peut sembler évident, mais il convient néanmoins de le souligner. Le filmstrip et le waterfall situé en-dessous sont directement liés :

Tout à gauche du filmstrip, vous voyez une ligne rouge verticale de 1 px. Lorsque vous faites défiler le filmstrip horizontalement, vous voyez la même ligne rouge se déplacer sur le waterfall. Ensemble, elles vous montrent à quoi la page ressemble exactement à cet endroit précis du waterfall (vous n’imaginez pas le temps qu’il m'a fallu pour remarquer cette fonctionnalité !).
Un autre repère visuel est cette bordure orange autour de certaines images. Elle signifie que quelque chose a changé par rapport l’écran précédent. C’est très utile si vous essayez d’identifier des changements mineurs entre les captures d’écran (comme le chargement d’une icône).
Vous pouvez voir ces deux fonctionnalités en action dans la capture d'écran. Une bordure orange autour de l'image à 0,9 s indique une modification majeure de la page par rapport à l’image à 0,8 s. En regardant de plus près le waterfall, nous pouvons voir la ligne rouge se approcher, et la ligne verte verticale (début du rendu). L'image à 0,9 s est en fait le moment du début du rendu de la page (Start Render).
Comment générer une vue personnalisée de waterfall
Presque toutes les images que vous voyez dans cet article font appel à cette fonctionnalité qui est cachée au bas de chaque graphe. WebPageTest vous donne la possibilité de personnaliser les éléments d’un waterfall :

En cliquant dessus, vous accédez aux options de personnalisation que vous voyez ci-après :

Comme vous le voyez, j’ai personnalisé ces éléments :
- Largeur de l’image
- Période de temps couverte par le waterfall (notez que cela revient à couper les requêtes qui arrivent plus tard dans le waterfall)
- Sélection des requêtes à montrer, individuellement ou par ensembles (les points de suspension représentent les éléments masqués)
- Case ‘Show CPU Utilization’ décochée pour masquer ‘CPU Utilisation’ et ‘Browser main thread’
Toutes ces options vous permettent de supprimer une grande partie du bruit dans le graphique afin de vous concentrer sur les informations à mettre en valeur.
Une fois que le visuel vous convient, cliquez simplement avec le bouton droit de la souris et enregistrez-le sur votre appareil.
Comment ajouter des points de repère personnalisés en utilisant la User Timing API
Voici une fonctionnalité utile que vous ne connaissiez peut-être pas. À l'aide de l'API User Timing, vous avez la possibilité de marquer certaines étapes du chargement de votre page. Ces points de repère seront enregistrés par WebPageTest et affichés dans les résultats. Par exemple, si vous voulez savoir quand le navigateur est arrivé à la fin de la balise <head>, vous pouvez ajouter le code suivant juste avant la balise de fermeture :
<head>
<!-- head stuff here... →
<script>window.performance.mark('mark_head_parsed');</script>
</head>
Le navigateur ajoutera alors un point de repère qui pourra être lu par WebPageTest. Le Run de WebPageTest affichera alors des résultats qui ressemblent à cela :

Comme vous pouvez le voir sur l'image ci-dessus, j'ai défini quatre points de repère sur la page, et l'un d'entre eux s'appelle mark_head_parsed.
Vous pouvez ajouter autant de marques que nécessaire, cela dépend vraiment de ce que vous essayez de mesurer. À présent, si vous vous cliquez sur le lien "customize waterfall”, vous verrez apparaître un ou plusieurs triangles violets et des lignes verticales. Ce sont les points de repères, ou marques, que nous venons de définir :

Dans l'image ci-dessus, les points de repère sont maintenant visibles (vous avez la possibilité de les activer / désactiver).
Mais peut-être que vous vous demandez pourquoi vous ne les voyez pas sur le waterfall interactif ? La raison est la suivante : les marques sont désactivées par défaut sur le graphique interactif. De nombreux JavaScript tiers incluaient des marques dans leur code, ce qui polluait le graphique avec beaucoup d'informations non pertinentes pour la plupart des utilisateur.rice.s de WebPageTest. Il a donc été décidé de désactiver la visibilité des marques par défaut. Elles ne sont désormais visibles que dans le lien "customize waterfall".
NB : Si vous exécutez une instance privée de WebPageTest, vous pouvez la configurer pour afficher par défaut les points de repère activées sur le waterfall interactif.
Conclusion
Voilà une “cascade” d’informations sur des aspects du waterfall qui me semblaient un peu obscurs ! Au fur et à mesure de mes explorations de scénarios sur WebPageTest, je les ajouterai à mon article. C’est un véritable exercice d’apprentissage pour moi aussi, si j’ai mal interprété ou qu’il manque certains points, faites-le moi savoir
Et si vous voulez en savoir plus sur WebPageTest, je vous recommande vivement l’ouvrage “Using WebPageTest” de Rick Viscomi, Andy Davies, Marcel Duran.
Découvrez ici comment mesurer et analyser votre webperf,
et comprendre les clés pour améliorer vos temps de chargement :

*Nous avons remplacé dans cet article “Négociation SSL” par “Négociation TLS” dans la mesure où SSL n’est plus utilisé